인사실로 이동하는 바람에 정신을 못차리고 있습니다.
이제는 데이터 분석과 HR 영역을 연계시켜 관련한 글을 올리고자 합니다.
저도 HR데이터는 생소하기에 고려대 교육학과 홍세희 교수님의 책을 참고하여 블로그에 남기겠습니다.
교수님의 경우, jamovi라는 프로그램으로 분석하였는데 R과 Python 등의 코드는 없어서 제가 그 역할을 대신 하고자 합니다.
대신 저는 회귀분석의 설명 대신 코드 위주로 작성하겠습니다.
Chapter 4 의 목적,
"임직원의 성과와 이에 영향을 줄 것으로 판단되는 여러 요인과의 관계를 알고 싶습니다. 각 요인이 성과에 긍정적 혹은 부정적 영향을 주는 지 통계적으로 확인할 수 있을까요? - 회귀분석(Regression) -
단순회귀 분석의 경우 독립변수와 종속변수의 관계를 밝히는 형태로 사용됩니다.
데이터 형태는 아래와 같습니다.
데이터(Data)
| ID | 성과 | 인센티브 | 직무교육시간 |
|---|---|---|---|
| 1 | 140 | 230 | 12 |
| 2 | 200 | 360 | 12 |
| 3 | 20 | 250 | 11 |
| 4 | 100 | 230 | 11 |
| 5 | 80 | 310 | 9 |
| 6 | 270 | 390 | 16 |
| 7 | 330 | 550 | 14 |
| : | : | : | : |
데이터 탐색
library(tidyverse)
df <- read_csv('Chapter4_Data/Chapter4_Data.csv', locale = locale(encoding = 'CP949'))
summary(df)
데이터 내 한글이 있는 경우 R에서는 코드 locale = locale(encoding = 'CP949')로 지정해주는 것이 좋습니다.
summary(df)로 데이터의 구성을 살펴보았습니다.

성과의 경우, 실무에서는 수치화되기 힘들겠지만 해당 데이터에서는 수치화되는 것으로 가정하였습니다.
3rd Qu.(3분위수)가 370인 반면 Max.(최대값)이 800으로 이상치처럼 보입니다.
다음은 결측치 데이터가 있는 지 살펴보았습니다.
colSums(is.na(df)) # 데이터 내 null값이 있는 지 확인
데이터 시각화
다음은 데이터에서 ① 인센티브에 따른 성과 ② 직무교육시간에 따른 성과를 살펴보겠습니다.
먼저, 인센티브에 따른 성과를 산점도로 보겠습니다.
theme_set(theme_gray(base_family = 'AppleGothic')) # MacBook 한글폰트 설정
ggplot(data = df) +
geom_point(aes(x = 인센티브, y = 성과)) +
labs(title = "인센티브과 성과의 관계",
x = "인센티브",
y = "성과")
먼저 맥북 사용 시 theme_set(theme_gray(base_family = 'AppleGothic')) 코드를 적용시켜 주어야 한글폰트가 깨지지 않고 잘 나타납니다.

그래프로 살펴보니 인센티브가 500 까지는 성과가 올라가다가 그 이후에는 감소하는 모습을 보입니다.
geom_smooth를 추가하면 더 보기 좋게 그릴 수 있습니다.
ggplot(data = df) +
geom_point(aes(x = 인센티브, y = 성과)) +
geom_smooth(aes(x = 인센티브, y = 성과)) +
labs(title = "인센티브과 성과의 관계",
x = "인센티브",
y = "성과")
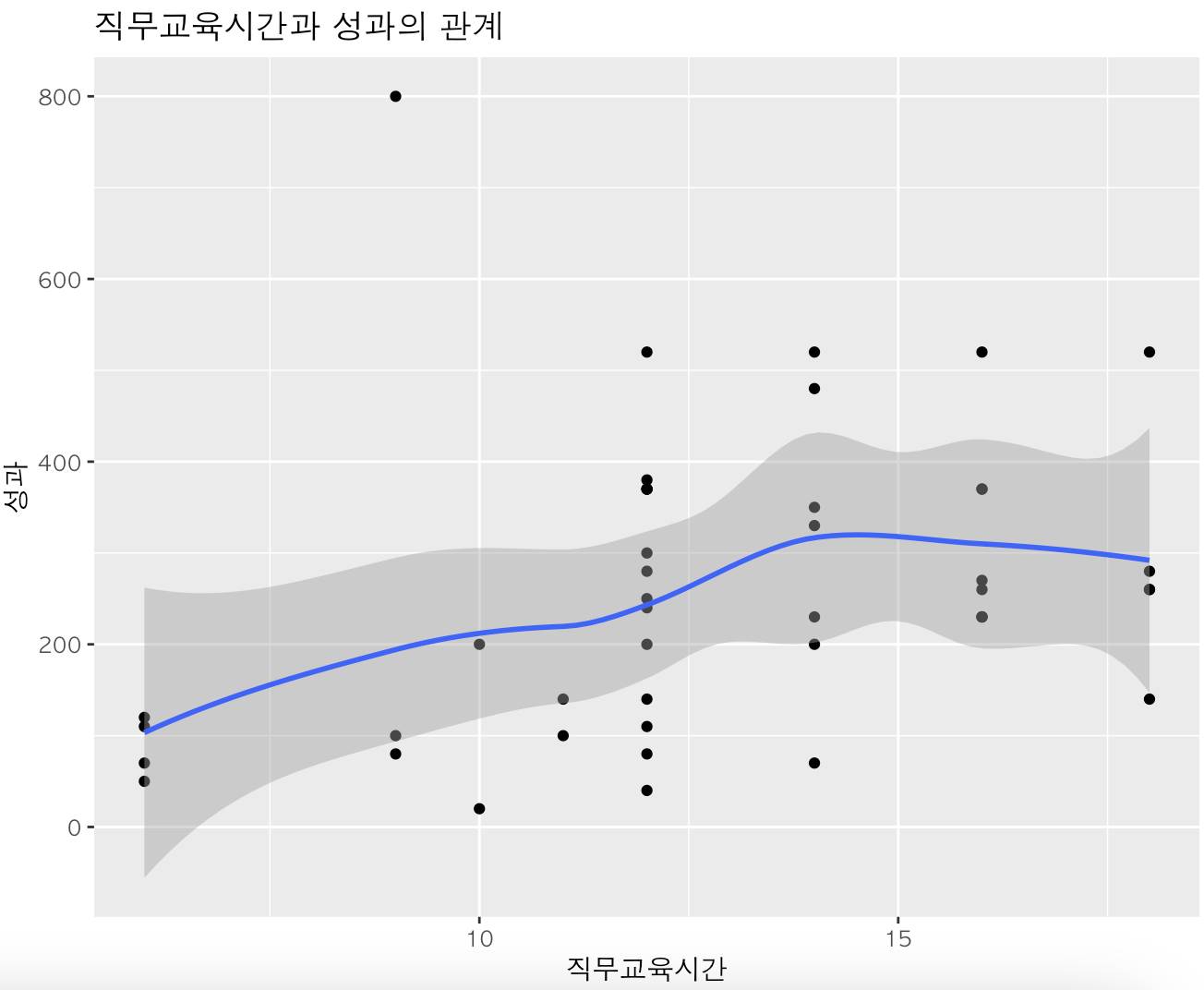
다음은 직무교육 시간에 따른 성과에 대해 산점도를 그려보겠습니다.
ggplot(data = df, aes(x = 직무교육시간, y = 성과)) + #x축, y축 동일한 경우 한 번에 그리기
geom_point() +
geom_smooth() +
labs(title = "직무교육시간과 성과의 관계",
x = "직무교육시간",
y = "성과")이번에는 위 코드와 다르게 aes를 ggplot 함수 내로 넣었습니다. x축과 y축이 동일한 경우에는 이렇게 한 번에 할 수 있습니다.
단순선형회귀 분석
- 인센티브에 따른 성과 단순회귀분석
incen_model = lm(data = df, formula = 성과 ~ 인센티브)
summary(incen_model)코드가 엄청 간단합니다 !
formula 부분에서 앞 부분에 종속변수인 성과를 ~ 뒷부분에 독립변수인 인센티브를 넣어주고 summary함수에 넣어주면 아래처럼 결과가 나타납니다.

• 절편 (Intercept): 126.6933
• 성능의 예상 값은 인센티브가 0일 때 약 126.6933입니다.
• p-값(Pr(>|t|)이 0.1032로, 일반적인 유의수준 (0.05)에서 통계적으로 유의하지 않습니다.
• 인센티브: 0.3005
• 인센티브가 한 단위 증가할 때 성과는 약 0.3005만큼 증가합니다.
• p-값(Pr(>|t|)이 0.0789로, 0.1 수준에서 통계적으로 유의합니다.
보통 p-값이 0.05 기준으로 많이 보기 때문에 인센티브가 성과에 유의미한 영향을 끼친다고 보기 어려울 수 있을 것 같습니다.
- 직무교육시간에 따른 성과 단순회귀분석
edu_model = lm(data = df, formula = 성과 ~ 직무교육시간)
summary(edu_model)
계수 (Coefficients)
• 절편 (Intercept): 50.946
• 성과의 예상 값은 직무교육시간이 0일 때 약 50.946입니다.
• p-값이 0.5872로, 일반적인 유의수준 (0.05)에서 통계적으로 유의하지 않습니다.
• 직무교육시간: 16.061
• 직무교육시간이 한 단위 증가할 때 성과는 약 16.061만큼 증가합니다.
• p-값이 0.0275로, 0.05 수준에서 통계적으로 유의합니다.
결정 계수 (R-squared)
• Multiple R-squared: 0.1081
• 설명된 변동의 비율은 약 10.81%입니다.(직무교육시간으로 성과를 10% 정도 설명할 수 있다로 봐주시면 됩니다)
요약
이 회귀 모델은 직무교육시간이 성과에 미치는 영향을 분석하고 있습니다. 직무교육시간 변수는 0.05 수준에서 통계적으로 유의하며, 직무교육시간이 증가할수록 성과도 증가하는 경향이 있습니다. 그러나 이 모델의 결정 계수는 낮아서, 직무교육시간 외에도 성과를 설명하는 다른 중요한 변수가 있을 수 있습니다.
다음에는 Python으로 단순선형회귀 분석을 HR Data에 어떻게 적용시키는 지 알아보겠습니다.
그리고 그 이후에는 일대일 방정식이 아니라, 다양한 요인이 성과에 어떻게 영향을 끼치는 지 어떤 변수가 가장 중요한 지 등을 알아볼 수 있는 다항회귀변수로 들고오겠습니다.
댓글