벌써 2023년이 왔습니다.
아침 카톡으로 동생이 짤을 보냈습니다.

믿기지 않아요 ..
그래서 저도 괜찮은 짤을 수집하기 위해서 구글이미지 크롤링을 시도했습니다.
1. 구글이미지 크롤링 코드공유
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
import time
import os
import urllib.request
import time
options = webdriver.ChromeOptions()
options.headless = True
wd = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options) # 셀레니움 실행 시 다운받아서 실행, 별도 업그레이드 시 설치필요 없음
query = input("검색어입력 : ")
if not os.path.exists(query):
os.mkdir(query)
url = f"https://www.google.com/search?q={query}&tbm=isch&sa=X&ved=2ahUKEwjrxoqWkKT0AhXkKqYKHQdbDsIQ_AUoAXoECAEQAw&biw=1707&bih=817&dpr=1.5"
wd.implicitly_wait(10)
wd.maximize_window()
wd.get(url)
# 무한 스크롤 처리
# 스크롤 전 높이
last_height = wd.execute_script("return window.scrollY")
# 무한 스크롤
while True:
# 맨 아래로 스크롤을 내린다.
wd.find_element(By.CSS_SELECTOR, "body").send_keys(Keys.END)
# 스크롤 사이 페이지 로딩 시간
time.sleep(1)
# 스크롤 후 높이
new_height = wd.execute_script("return window.scrollY")
if new_height == last_height:
break
last_height = new_height
# 썸네일 이미지 태그 추출
imgs = wd.find_elements(By.CSS_SELECTOR, ".rg_i.Q4LuWd")
for i, img in enumerate(imgs, 1):
# 이미지를 클릭해서 큰 사이즈를 찾아요
img.click()
time.sleep(1)
# 큰 이미지 주소 추출
if i == 1:
target = wd.find_elements(By.CSS_SELECTOR, "img.n3VNCb")[0]
else:
target = wd.find_elements(By.CSS_SELECTOR, "img.n3VNCb")[1]
img_src = target.get_attribute('src')
# 이미지 다운로드
# 크롤링 하다보면 HTTP Error 403: Forbidden 에러가 납니다.
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent', 'Mozila/5.0')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(img_src, f'{query}/{i}.jpg')input에 검색하고 싶은 걸 넣으면 원하는 파일을 볼 수 있습니다.
저는 "30살 놀리는 짤"로 돌렸고, 이미지는 다음과 같이 다운받을 수 있었습니다.
아래서 코드설명 하겠습니다.
2. 구글이미지 다운로드(크롤링 결과)
3. 라이브러리 설명
#셀레니움 실행도구
from selenium import webdriver # 크롬드라이버를 실행시키기 위한 라이브러리(셀레니움 기본)
#명령어 입력도구
from selenium.webdriver.common.keys import Keys #ENTER 등의 동작을 위해 필요
from selenium.webdriver.common.by import By #CSS, XPATH 등의 경로 파악을 위해 필요(업데이트 되면서 By.CSS_SELECTOR 와 같은 형태로 써야합니다.)
#셀레니움 자동설치도구 : 셀레니움 업데이트 시 변경해줘야하는 번거로움 존재합니다. 그래서 실행할 때 자동설치하는 라이브러리입니다.
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
#Service는 아래와 같이 사용됩니다.
options = webdriver.ChromeOptions()
options.headless = True
wd = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
#예외처리 라이브러리
from selenium.common.exceptions import NoSuchElementException
#셀레니움 외 기타 라이브러리
import time #시간지연등에 필요
import os #파일경로 및 생성 필요
import urllib #이미지 파일 저장 시 필요# 주석으로 각 라이브러리별 필요성 등에 대하여 정리하였습니다.
4. 아래로 스크롤하는 코드
# 스크롤 전 높이
last_height = wd.execute_script("return window.scrollY")
# 무한 스크롤
while True:
# 맨 아래로 스크롤을 내린다. (키보드의 END키를 누르는 효과입니다.)
wd.find_element(By.CSS_SELECTOR, "body").send_keys(Keys.END)
# 스크롤 사이 페이지 로딩 시간
time.sleep(1)
# 스크롤 후 높이
new_height = wd.execute_script("return window.scrollY")
if new_height == last_height: # 스크롤 후 높이(new_height)가 스크롤 전 높이(last_height와 같다면 멈춤)
break
last_height = new_height #그렇지 않으면 스크롤 후 높이를 스크롤 전 높이로 재할당
execute_script의 경우, JavaScript언어라고 합니다.
웹페이지의 현재 높이를 측정한다고 합니다.
이미지 CSS 코드
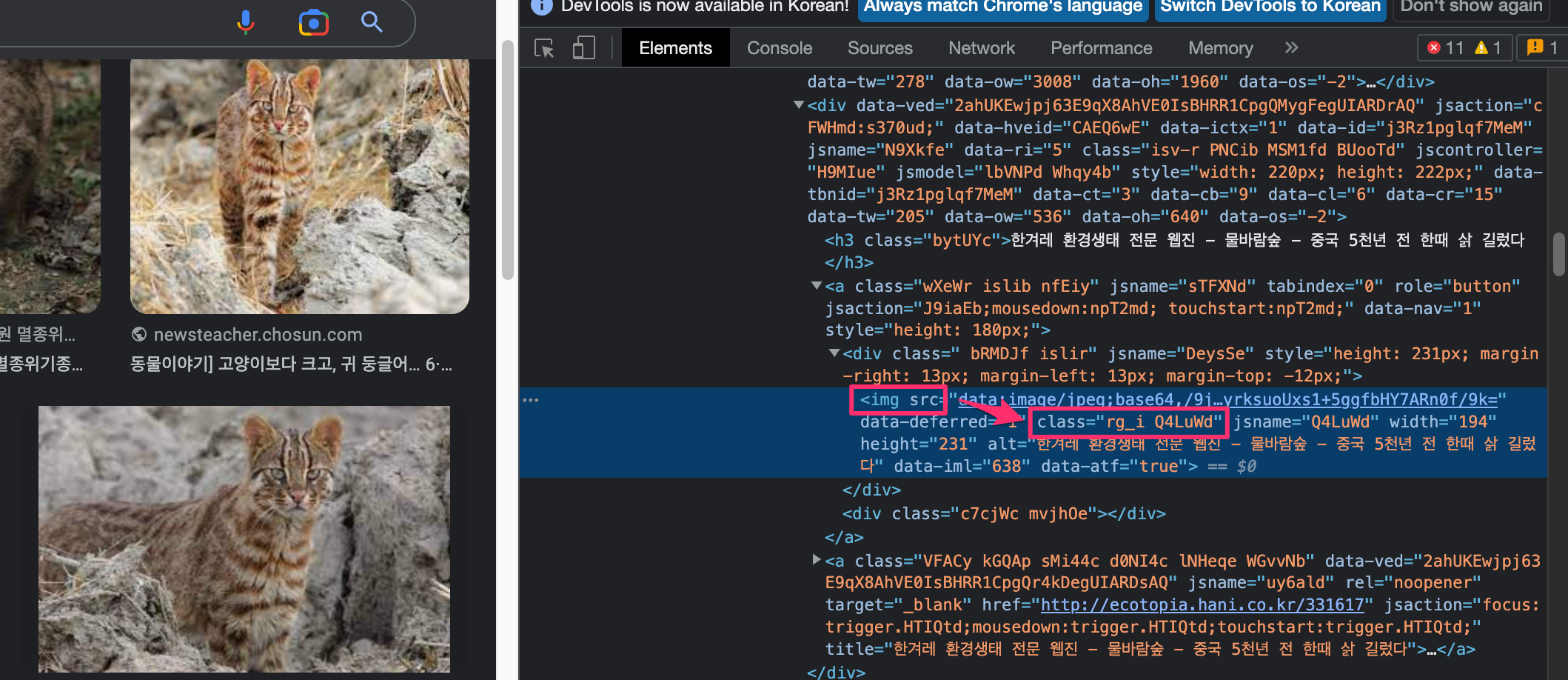
F12버튼 클릭 후, 해당 아이콘을 클릭합니다.

후에 원하는 이미지에 마우스를 옮겨두고 좌클릭하면 이미지 소스코드가 나타납니다.
이미지 소스코드에서 CLASS 코드를 사용할껀데 보시면 class = "rg_i Q4LuWd" 로 나타납니다.
5. CSS SELECTOR 사용법
- tag name : "tag_name" (태그 이름을 그대로 써서 접근)
- tag id 접근 : "#tag_id" (태그 id이름 앞에 #을 써서 접근)
- tag class 접근 : ".tag_class" (태그 class이름 앞에 .을 써서 접근)
- * 이름내부에 띄어쓰기가 있을 때 : 띄어쓰기 부분에 .을 찍어줍니다
현재 class 코드가 "rg_i Q4LuWd"인데 반드시 띄워쓰기 부분은 .으로 붙여써줘야 합니다.
"rg_i Q4LuWd" → "rg_i.Q4LuWd"
class는 앞에 .을 붙여줘야합니다.
"rg_i.Q4LuWd" → ".rg_i.Q4LuWd" (최종)
최종적으로 .rg_i.Q4LuWd 을 class로 찾아야 합니다.
# 썸네일 이미지 태그 추출
imgs = wd.find_elements(By.CSS_SELECTOR, ".rg_i.Q4LuWd")
for i, img in enumerate(imgs, 1):
img.click()
time.sleep(1)
# 큰 이미지 주소 추출
if i == 1:
target = wd.find_elements(By.CSS_SELECTOR, "img.n3VNCb")[0]
else:
target = wd.find_elements(By.CSS_SELECTOR, "img.n3VNCb")[1]
img_src = target.get_attribute('src')
# 이미지 다운로드
# 크롤링 하다보면 HTTP Error 403: Forbidden 에러가 납니다.
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent', 'Mozila/5.0')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(img_src, f'{query}/{i}.jpg')img에 대해서 list로 받았으니 반복문을 돌며 하나씩 다운로드 합니다.
url 다운로드의 경우 urlretrieve를 사용하면 됩니다.
6. URL 다운로드
import urllib.request
urllib.request.urlretrieve(URL, "저장경로")
7. 크롤링 결과 GIF
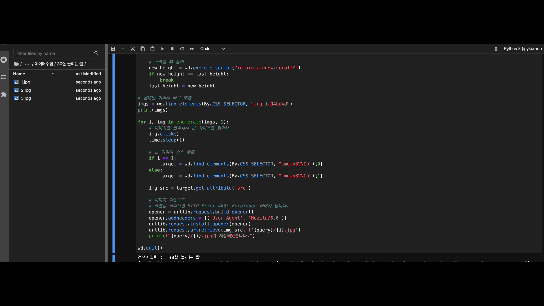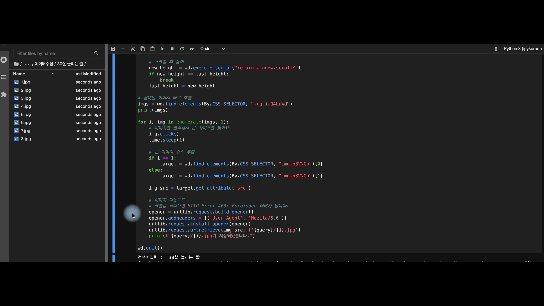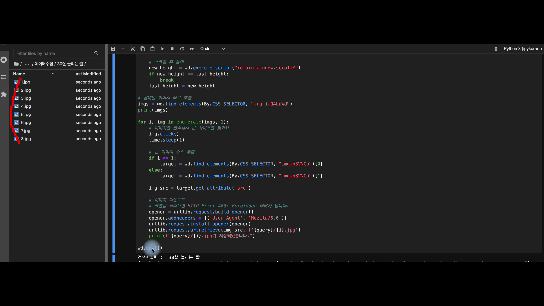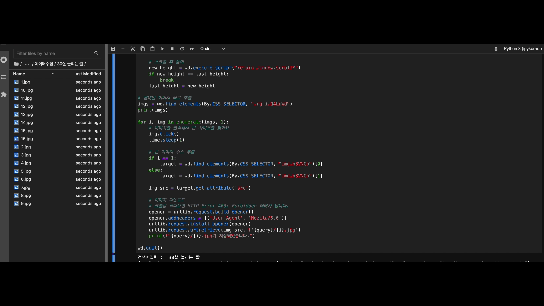
영상을 찍은 뒤 gif 변환하는데 매번 이렇게 화질이 안예쁘게 나오네요.
예쁘게 하는 법 아시는 분 댓글로 알려주세요
구글 이미지 자동 다운로드 도전 해보시길 바랍니다 ~
'파이썬(Python)' 카테고리의 다른 글
| [파이썬 / Python ] Prophet 함수로 블로그 방문자수를 예측해보자 (1) | 2023.01.26 |
|---|---|
| [파이썬/Python] '아바타2 : 물의 길' 댓글 수집 및 리뷰 분석해보기 (0) | 2023.01.03 |
| [파이썬/Python] 파이썬으로 폴더 내 엑셀파일 한번에 통합하기 (0) | 2022.11.22 |
| [파이썬/Python] 영화('동감') 댓글 리뷰 워드 클라우드(wordcloud)로 만들어보기 (0) | 2022.11.20 |
| [파이썬/Python] 날짜지만 소수점인 데이터 날짜로 변경해보기(10월이 1월로 변경되지 않도록 하기) (0) | 2022.11.15 |




댓글