데이터를 활용할 때 빈도수를 구하고 싶을 때가 있습니다.
오늘은 Python Pandas 로 쉽고 빠르게 빈도수 구하는 방법 2가지를 알아볼 예정입니다.
데이터 로드하기
먼저 Seaborn 라이브러리를 사용하여 내장 데이터를 로드하도록 하겠습니다.
# Library import
import pandas as pd
import seaborn as sns # 그래프 시각화 함수지만 내장데이터 불러오는 용도로 사용
# Dataset import
df = sns.load_dataset('titanic') # 타이타닉 데이터를 df라는 변수에 담았습니다.
df.head()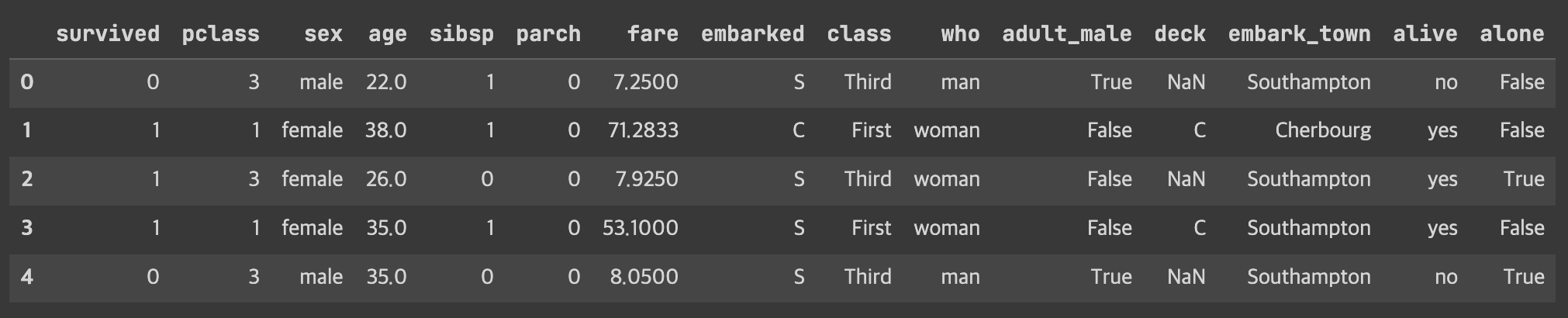
구간함수는 연속형 변수에서 사용할 예정이기 때문에, 바꿔볼 데이터는 age 열과 fare 열을 활용하겠습니다.
함수 사용하지 않고 나이대를 구분해보기
제가 예전에 자주 사용하던 방법입니다.
age 1행에 있는 22를 20대로 38을 30대로 변경해보도록 하겠습니다.
(df['age'] // 10) * 10Python에서 // 은 몫을 구하는 연산입니다.
먼저 df['age']에서 // 연산을 통해 몫을 구합니다. 예를 들면 22를 10으로 나눈 몫은 2입니다. (몫 2 나머지 2, 2(몫) * 10 + 2(나머지) )
* 는 곱하기 입니다. 2로 나온 몫을 10을 곱해서 20으로 바꿔줍니다.

연산만으로도 연속형 변수를 범주형으로 바꿀 수 있습니다.
pd.cut을 이용하여 구간별 범주 구해보기 ①
age_bins = [0, 10, 18, 30, 55, 100]
cats = pd.cut(df['age'], age_bins, right = False)먼저 age_bins라는 변수를 리스트형으로 원하는 범위를 만들어줍니다.
저는 0세 이상 ~ 10세 미만, 10세 이상 ~ 18세 미만, 18세 이상 ~ 30세 미만, 30세 이상 ~ 55세 미만, 55세 이상 ~ 100세 미만 이런 식으로 만들기 위하여 age_bins = [0, 10, 18, 30, 55, 100] 으로 만들었습니다.
pd.cut 함수 내에 df['age']를 넣어주시고, 변수인 age_bins를 넣어줍니다. right = False를 통해 오른쪽에 들어오는 숫자가 미만으로 나오게끔 해줍니다. right = False를 지정하여 구간 값에 오른 쪽 값이 미만으로 만들어줬습니다.
예를 들어 right = True인 경우( 이 경우가 기본값입니다 ) 0세 초과 ~ 10세 이하 입니다.
'이상'의 경우 해당 숫자를 포함하고, '초과'의 경우 해당 숫자를 포함하지 않습니다.
'이하'의 경우 해당 숫자를 포함하고, '미만'의 경우 해당 숫자를 포함하지 않습니다.
어떻게 결과가 나오는지 한번 살펴보겠습니다.
df['age_cats'] = cats
df[['age', 'age_cats']]
22세의 경우, 18세 이상 ~ 30세 미만으로 잘 나왔습니다.
age_cats 열의 경우 [18.0, 30.0) 으로 좌우 괄호가 다른 게 확인됩니다. [ ] 이상 이하이며, ( ) 초과 미만 입니다.
[18.0, 30.0) 의 경우 18세 이상 30세 미만입니다.
다른 구간값들을 보더라도 잘 분류된 것을 볼 수 있습니다.
value_counts라는 함수를 통해 구간별 값의 개수가 얼마나 되는 지 확인할 수 있습니다.

value_counts()함수로 숫자 카운팅이 아니라 비율로 보고 싶을 수도 있습니다.
그런 경우에는 내부에 normalize = True를 작성해주시면 됩니다.

pd.cut을 이용하여 구간별 범주 label 달아보기 ②
범주화를 잘 진행하였으나, 팀원들에게 공유했을 때나 다른 사람들이 봤을 때 해당 내용을 모른다면 [18, 30) 에 대한 추가설명이 필요합니다. 이런 경우에는 label로 이름 변경이 가능합니다.
# 5개 카테고리로 범주화 진행하였던 내용을 새로운 변수명으로 지정해줍니다.
# ex) 0세 이상 ~ 10세 미만 : child
group_names = ['child', 'teenager', 'young_adult', 'adult', 'elderly']
# label함수에 group_names 변수를 넣어줍니다.
df['age_cat_label'] = pd.cut(df.age, age_bins, right = False, labels = group_names)
df[['age', 'age_cats', 'age_cat_label']].head()
앞서 이야기 했던 내용처럼 0세 이상 18세 미만은 child로 10세 이상 18세 미만은 teenager로 18세 이상 30세 미만은 young_adult로 잘 변경되었습니다.
value_counts 함수로 확인해보아도 동일한 숫자가 나오네요

pd.cut으로 연속된 범위 알아서 짤라줘
매번 범위를 지정해서 짤라내기 번거로울 수 있습니다.
그럴 때는 5개 구간으로 등분해서 보여달라고 요구할 수 있습니다.
예를 들어 1 ~ 100까지 숫자 범위가 지정되어 있는 데이터에 5개로 등분해달라고 요청한다면
1 ~ 20 / 21 ~ 40 / 41 ~ 60 / 61 ~ 80 / 81 ~ 100 으로 범위를 설정하고 등분할 수 있습니다.
이런 경우에는 저희가 범위를 지정해주지 않아도 쉽게 pandas를 통해 구분할 수 있습니다.
이번에는 범위가 조금 큰 fare(요금) 열을 사용해서 진행해보겠습니다.
먼저 describe 함수를 통해 대략적인 분포를 확인할 수 있습니다.


히스토그램으로 보니 조금 더 직관적으로 보입니다. 대부분이 100달러 미만 요금에 있고, 최대 500달러 수준까지 있습니다.
평균이 32달러이고 최대금액이 512달러 이기 때문에 등분한다면 한 쪽에 치중된 데이터 밖에 얻을 수 없을 것 같습니다. 100달러 미만의 데이터가 대부분일 것 같네요
이럴 경우, 데이터의 빈도수를 5등분 하는 방법이 바로 qcut을 사용하는 겁니다.
df['fare_cat_q'] = pd.qcut(df.fare, 5)fare열 총 891개를 5등분해서 들어갈 수 있게 해줍니다.
891 나누기 5의 경우, 178.2 나오네요. 178로 딱딱 떨어지게는 못 나눠도 대충 그 비슷하게 나눠줍니다.

qcut에는 right 함수가 없어서 이상 미만을 변경할 수 없습니다.
다만 precision 및 label은 가능합니다.
precision은 소수점 개수를 얼마나 보여줄 지 정할 수 있습니다.

label 해보기
label의 경우 pd.cut과 동일하게 진행해주시면 됩니다.
fare_label = ['very_cheap', 'cheap', 'moderate', 'exp', 'very_exp']
df['fare_cat_q_label'] = pd.qcut(df['fare'], 5, labels = fare_label)
df[['fare', 'fare_cat_q', 'fare_cat_q_label']].head()
pd.qcut 범위 지정해보기
qcut도 등분만 있는 게 아닙니다. 사용자 지정으로 변경 가능합니다.
df['fare_cat_q'] = pd.qcut(df.fare, [0, 0.1, 0.25, 0.5, 0.9, 1], precision = 0)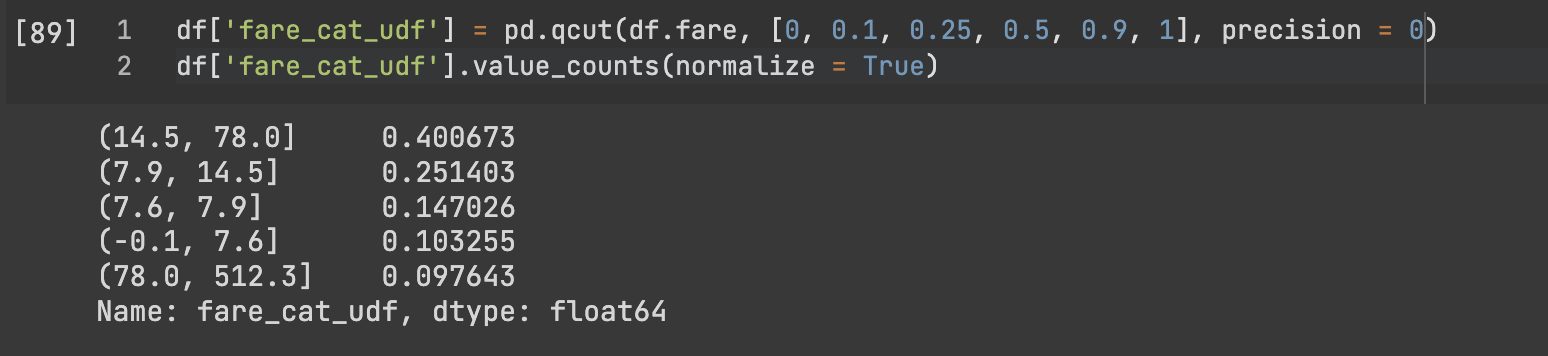
해당 비중으로 잘 나눠진 것을 볼 수 있습니다.
구간별 빈도수 확인 시 pd.cut 과 pd.qcut 잘 활용해보시길 바랍니다.
'파이썬(Python)' 카테고리의 다른 글
| Python 데이터를 엑셀에 붙여넣기 / 엑셀 데이터를 파이썬에 붙여넣기 (0) | 2024.08.05 |
|---|---|
| 파이썬으로 가상의 데이터 만들기(Feat. Faker) (0) | 2023.07.16 |
| [Python] Jupyterlab 자동 괄호닫기, 따옴표 닫기 설정 (0) | 2023.01.27 |
| [파이썬 / Python ] Prophet 함수로 블로그 방문자수를 예측해보자 (1) | 2023.01.26 |
| [파이썬/Python] '아바타2 : 물의 길' 댓글 수집 및 리뷰 분석해보기 (0) | 2023.01.03 |




댓글