엑셀 블로그를 할 때 어려운 부분 중 하나는 바로 예시 자료입니다.
예시 자료를 만들려고 생각하는 게 시간이 은근 많이 잡아 먹습니다.
그래서 앞으로 예시자료는 크롤링한 자료를 통해서 보여주고자 멜론차트 크롤링을 진행해보았습니다.
근데 멜론차트 언뜻 보기에 정적페이지처럼 보여서 되게 난이도가 낮을 거라고 생각하여 도전하였는데, BeatuifulSoup으로 진행 시 '좋아
요' 숫자가 안나타났습니다.
01. '정적'페이지와 '동적'페이지 구분하기
동적페이지와 정적페이지 유무가 스크롤을 움직이는 유무인 줄 알았으나 그게 아니었습니다
'페이지 소스코드'로 보이는 값이 나타나면 정적페이지, 그게 아니라면 '동적 페이지' 입니다
예를 들어 멜론차트를 보게되면

취중고백 김민석의 경우, 146,713건이라는 좋아요 숫자가 표시됩니다
근데 '페이지 소스보기'를 통해서 본 경우(마우스 우클릭하면 나옵니다)


나머지는 전부 잘 나타나나 좋아요 숫자만 동적으로 구성해두었습니다.
이런 경우에는 BeautifulSoup로 불러올 수 없습니다.
02. BeautifulSoup으로 정적페이지 크롤링하기
코드는 다음과 같습니다.
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = "https://www.melon.com/chart/index.htm"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
title = []
artist = []
album = []
like = []
total_p1 = soup.find_all('tr', attrs = {'class' : 'lst50'})
for idx, total in enumerate(total_p1) :
title_50 = total.find('div', attrs = {'class' : 'ellipsis rank01'}).get_text().strip()
artist_50 = total.find('span', attrs = {'class' : 'checkEllipsis'}).get_text().strip()
album_50 = total.find('div', attrs = {'class' : 'ellipsis rank03'}).get_text().strip()
like_50 = total.find('button', attrs = {'class' : 'button_etc like'})
like_50 = like_50.find('span', attrs = {'class' : 'cnt'})
title.append(title_50)
artist.append(artist_50)
album.append(album_50)
like.append(like_50)
rank_df = pd.DataFrame({'Title' : title,
'Artist' : artist,
'Album' : album,
'Like' : like})
rank_df.head(20)여기서도 like_50이라는 코드를 통해 불러오려고 했지만 결과적으론 실패하였습니다.

Like행을 보시면 총건수 및 특수문자들로 나타나고 있습니다.
혹시나 하는 마음에 Like의 한 행만 별도로 보았습니다.

03. Selenium으로 동적페이지 크롤링하기
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
import pandas as pd
chrome_options = webdriver.ChromeOptions()
chrome_options.headless = True
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
# url
driver.get('https://www.melon.com/chart/index.htm')
driver.implicitly_wait(10)
# name 속성 값으로 특정 태그 찾기
elements = driver.find_elements(By.CLASS_NAME, "lst50")
# 빈 리스트
title_list = []
artist_list = []
album_list = []
like_num_list = []
#크롤링하기
for element in elements :
title = element.find_element(By.CLASS_NAME, "ellipsis.rank01").text
artist = element.find_element(By.CLASS_NAME, "ellipsis.rank02").text
album = element.find_element(By.CLASS_NAME, "ellipsis.rank03").text
like_num = element.find_element(By.CLASS_NAME, "cnt").text.replace(",","") # like_num이 동적페이지
title_list.append(title)
artist_list.append(artist)
album_list.append(album)
like_num_list.append(like_num)
time.sleep(1) # 너무 빠르게 크롤링할 시 사이트 무리, 속도조절
print(title, artist, album, like_num)
melon_df = pd.DataFrame({"title" : title_list,
"artist" : artist_list,
"album" : album_list,
"like_num" : like_num_list})
# print(melon_df)
driver.quit()[꿀팁] Selenium 4.0으로 바뀌면서 코드를 무조건 By.~~ 이런 형태로 작성하셔야 합니다.
from selenium.webdriver.common.by import By
#driver.find_element(By.<속성>, '<속성 값>')
driver.find_element(By.XPATH, "text")
driver.find_element(By.XPATH, "text")
driver.find_element(By.ID, "text")
driver.find_element(By.LINK_TEXT, "text")
driver.find_element(By.PARTIAL_LINK_TEXT, "text")
driver.find_element(By.NAME, "text")
driver.find_element(By.TAG_NAME, "text")
driver.find_element(By.CLASS_NAME, "text")
driver.find_element(By.CSS_SELECTOR, "text")
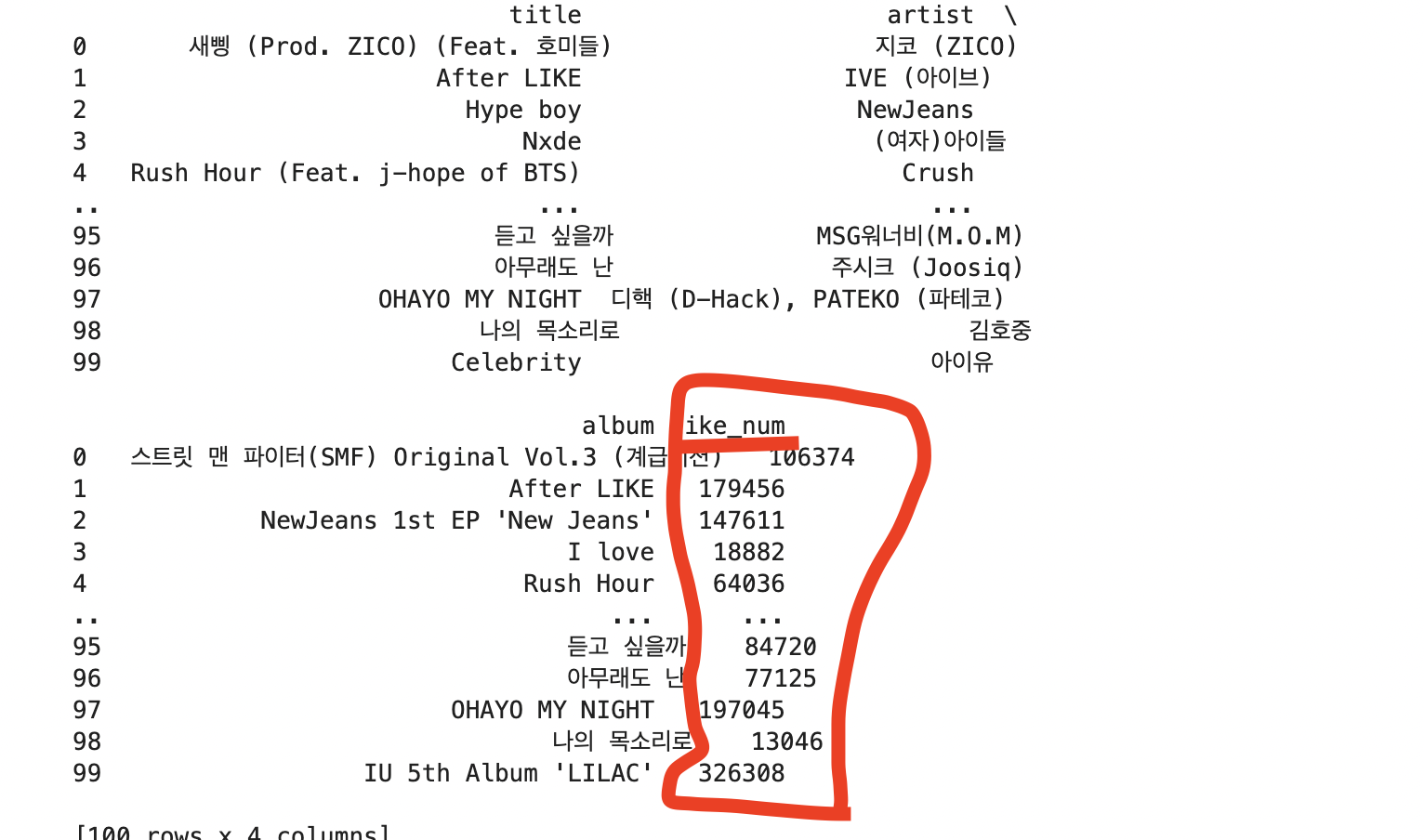
Selenium으로 할 경우, 동적페이지도 크롤링 됩니다.
'좋아요' 숫자도 잘 나오는 걸 볼 수 있습니다.
앞으로 이 예시를 통해 엑셀 파일의 예시를 적극 이용하도록 하겠습니다.
'파이썬(Python)' 카테고리의 다른 글
| [파이썬/Python] 날짜지만 소수점인 데이터 날짜로 변경해보기(10월이 1월로 변경되지 않도록 하기) (0) | 2022.11.15 |
|---|---|
| [파이썬/Python] 분리된 엑셀 시트 하나의 시트로 통합하기 (0) | 2022.11.06 |
| [Python] 정규표현식을 통한 숫자형태 변환 replace 함수활용 (1) | 2022.10.04 |
| [파이썬(Python)] 파이썬으로 엑셀 작동하기_조작방법(openpyxl) (0) | 2022.10.02 |
| [한산-용의 출현] 댓글 수집하기 (0) | 2022.08.01 |




댓글